惨遭 DruidDataSource 和 Mybatis 暗算,导致 OOM
异常分析
2020-01-22
2960
1
先遭DruidDataSource袭击
事发
一个平凡的工作日,我像往常一样完成产品提出的需求的业务代码,突然收到了监控平台发出的告警信息。本以为又是一些业务上的 bug 导致的报错,一看报错发现日志写着java.lang.OutOfMemoryError: Java heap space。
接着我远程到那台服务器上,但是卡的不行。于是我就用top命令查了一下 cpu 信息,占用都快要到 99%了。再看看 GC 的日志发现程序一直在 Full GC,怪不得 cpu 占用这么高。
这里就推测是有内存泄漏的问题导致 GC 无法回收内存导致OOM。为了先不影响业务,就先让运维把这个服务重启一下,果然重启后服务就正常了。
分析日志
先看一下报错日志详细写了一些什么错误信息,虽然一般OOM问题日志不能准确定位到问题,但是已经打开日志平台了,看一下作为参考也是不亏的。
看到日志中写的OOM事发场景是在计算多个用户的总金额的时候出现的,大致伪代码如下:
/**
* OrderService.java
*/
// 1. 根据某些参数获取符合条件的用户 id 列表
List<Long> customerIds = orderService.queryCustomerIdByParam(param);
// 2. 计算这些用户 id 的金额总和
long principal = orderMapper.countPrincipal(customerIds);
<!--
OrderMapper.xml
-->
<!-- 3. 在 OrderMapper 的 xml 文件中写 mybatis 的 sql 逻辑 -->
<select id="countPrincipal" resultType="java.lang.Long">
select
IFNULL(sum(remain_principal),0)
from
t_loan where
<if test="null != customerIds and customerIds.size > 0">
customer_id in
<foreach collection="customerIds" item="item" index="index" open="("
close=")" separator=",">
#{item}
</foreach>
</if>
</select>
这部分感觉出问题的原因是由于计算金额总额时,查询参数customerIds太多了。由于前段时间业务的变更,导致在参数不变的情况下,查询出的customerIds列表由原来的几十几百个 id 变成了上万个,就我看的报错信息这里的日志打印出来这个 list 的大小就有三万多个customerId。不过就算查询条件为三万多个而导致 sql 执行的比较慢,但是这个方法只有内部的财务系统才会调用,业务量没那么大,也不应该导致OOM的出现啊。 所以接着再看一下JVM打印出来的 Dump 文件来定位到具体的问题。
分析 Dump 文件
得益于在 JVM 参数中加了-XX:+HeapDumpOnOutOfMemoryError参数,在发生OOM的时候系统会自动生成当时的 Dump 文件,这样我们可以完整的分析“案发现场”。这里我们使用 Eclipse Memory Analyzer 工具来帮忙解析 Dump 文件。
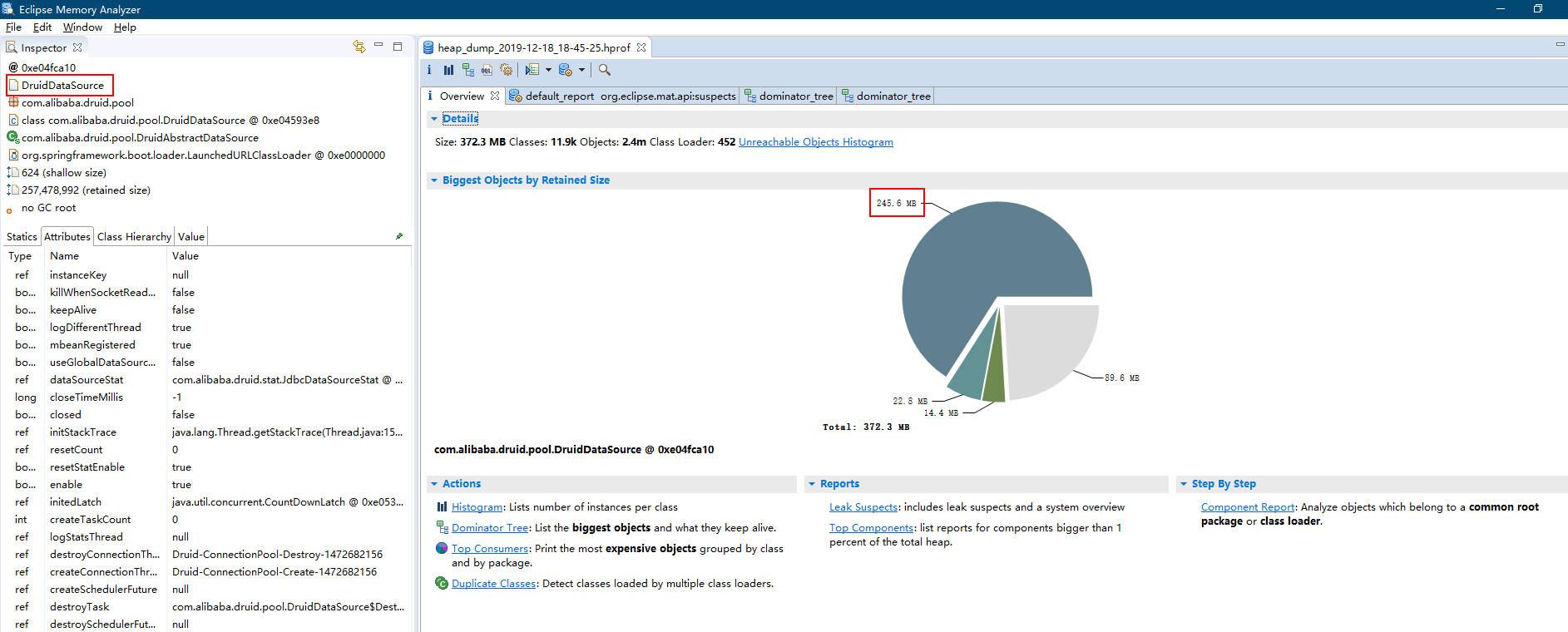
从 Overview 中的饼图可以很明显的看到有个蓝色区域占了最大头,这个类占了 245.6MB 的内存。再看左侧的说明写着DruidDataSource,好的,罪魁祸首就是他了。
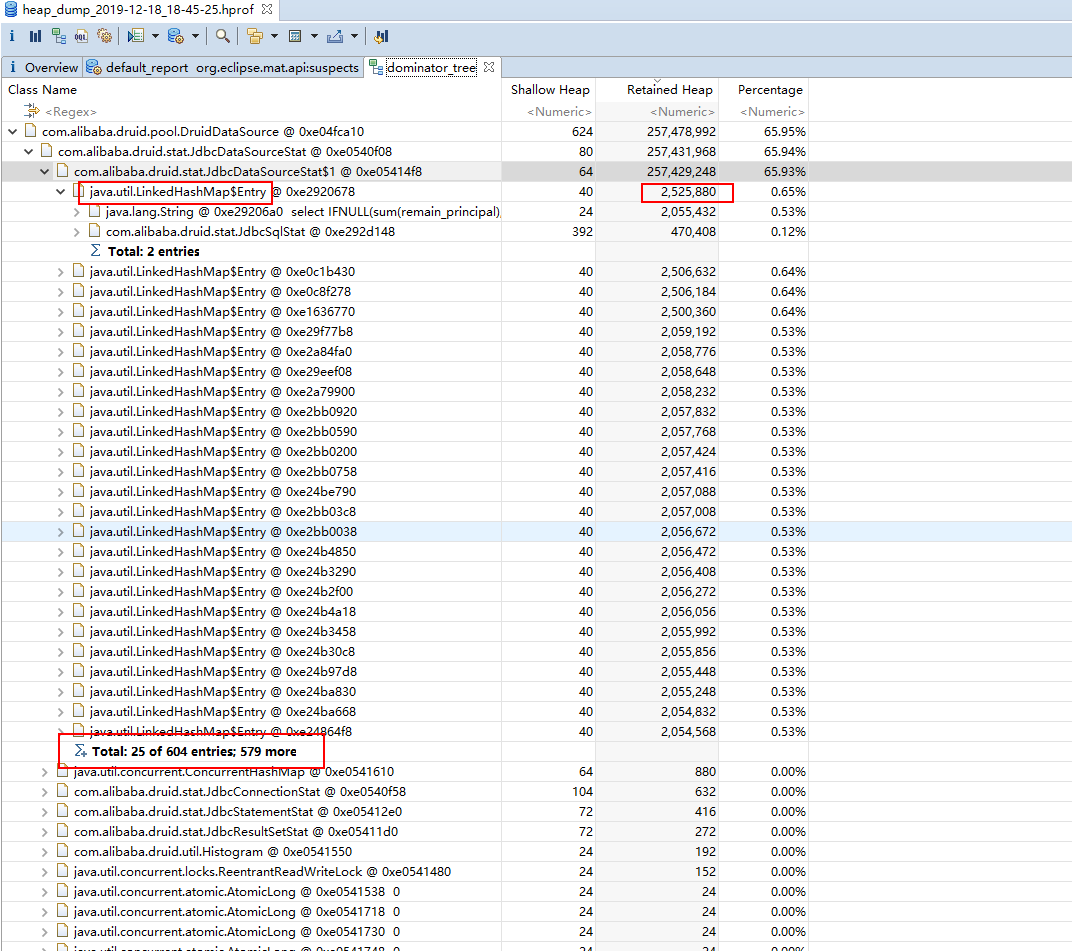
再通过 Domainator_Tree 界面可以看到是com.alibaba.druid.pool.DruidDataSource类下的com.alibaba.druid.stat.JdbcDataSourceStat$1对象里面有个 LinkedHashMap,这个 Map 持有了 600 多个 Entry,其中大约有 100 个 Entry 大小为 2000000 多字节(约 2MB)。而 Entry 的 key 是 String 对象,看了一下 String 的内容大约都是select IFNULL(sum remain_principal),0) from t_loan where customer_id in (?, ?, ?, ? ...,果然就是刚才错误日志所提示的代码的功能。
问题分析
由于计算这些用户金额的查询条件有 3 万多个所以这个 SQL 语句特别长,然后这些 SQL 都被JdbcDataSourceStat中的一个 HashMap 对象所持有导致无法 GC,从而导致OOM的发生。 嗯,简直是教科书般的OOM事件。
处理
接下来去看了一下JdbcDataSourceStat的源码,发现有个变量为LinkedHashMap<String, JdbcSqlStat> sqlStatMap的 Map。并且还有个静态变量和静态代码块:
private static JdbcDataSourceStat global;
static {
String dbType = null;
{
String property = System.getProperty("druid.globalDbType");
if (property != null && property.length() > 0) {
dbType = property;
}
global = new JdbcDataSourceStat("Global", "Global", dbType);
}
这就意味着除非手动在代码中释放global对象或者remove掉sqlStatMap里的对象,否则sqlStatMap就会一直被持有不能被 GC 释放。
已经定位到问题所在了,不过简单的从代码上看无法判定这个sqlStatMap具体是有什么作用,以及如何使其释放掉,于是到网上搜索了一下,发现在其 Github 的 Issues 里就有人提出过这个问题了。每个 sql 语句都会长期持有引用,加快 FullGC 频率。
sqlStatMap这个对象是用于Druid的监控统计功能的,所以要持有这些 SQL 用于展示在页面上。由于平时不使用这个功能,且询问其他同事也不清楚为何开启这个功能,所以决定先把这个功能关闭。
根据文档写这个功能默认是关闭的,不过被我们在配置文件中开启了,现在去掉这个配置就可以了
<bean id="dataSource" class="com.alibaba.druid.pool.DruidDataSource"
init-method="init" destroy-method="close">
...
<!-- 监控 -->
<!-- <property name="filters" value="state"/> -->
</bean>
修改完上线后一段时间后没有发生OOM了,这时再通过jmap -dump:format=b,file=文件名 [pid]命令生成 Dump 文件,会发现内存占用恢复正常,并且也不会看到com.alibaba.druid.pool.DruidDataSource类下有com.alibaba.druid.stat.JdbcDataSourceStat$1的占用。证明这个OOM问题已经被成功解决了。
再遭Mybatis暗算
事发
又是一个平凡的工作日,线上告警又出现报错,我一看日志又是OOM。我以为上次DruidDataSource问题还没解决干净,但是这次的现象却有点不一样。首先是这次只告警了一次,不像上次一直在告警。然后远程到服务器看 cpu 和内存占用正常,业务也没有受影响,所以这次也不用重启服务了。
分析
这次告警的错误日志还是指向着上次DruidDataSource导致OOM异常的位置,由于对其印象深刻,所以这次直接看看 Dump 文件(由于 Dump 文件比较大,线上的被清除了,而我也忘记备份,所以这份文件是我时候场景还原的时候生成的)。
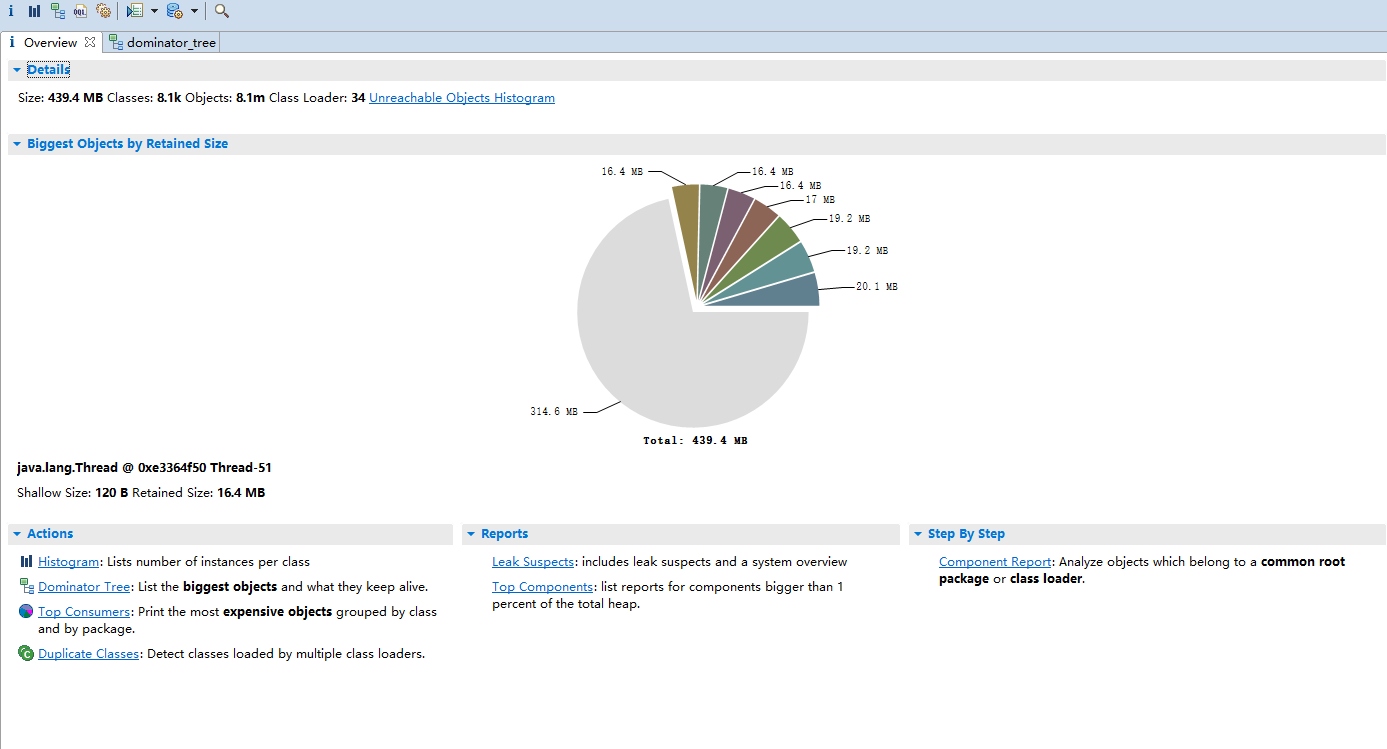
这次没有明显的一个特别大的占用对象了,看来这次的问题确实和上次有所不一样。再去看看 Domainator_Tree 界面的具体分析。
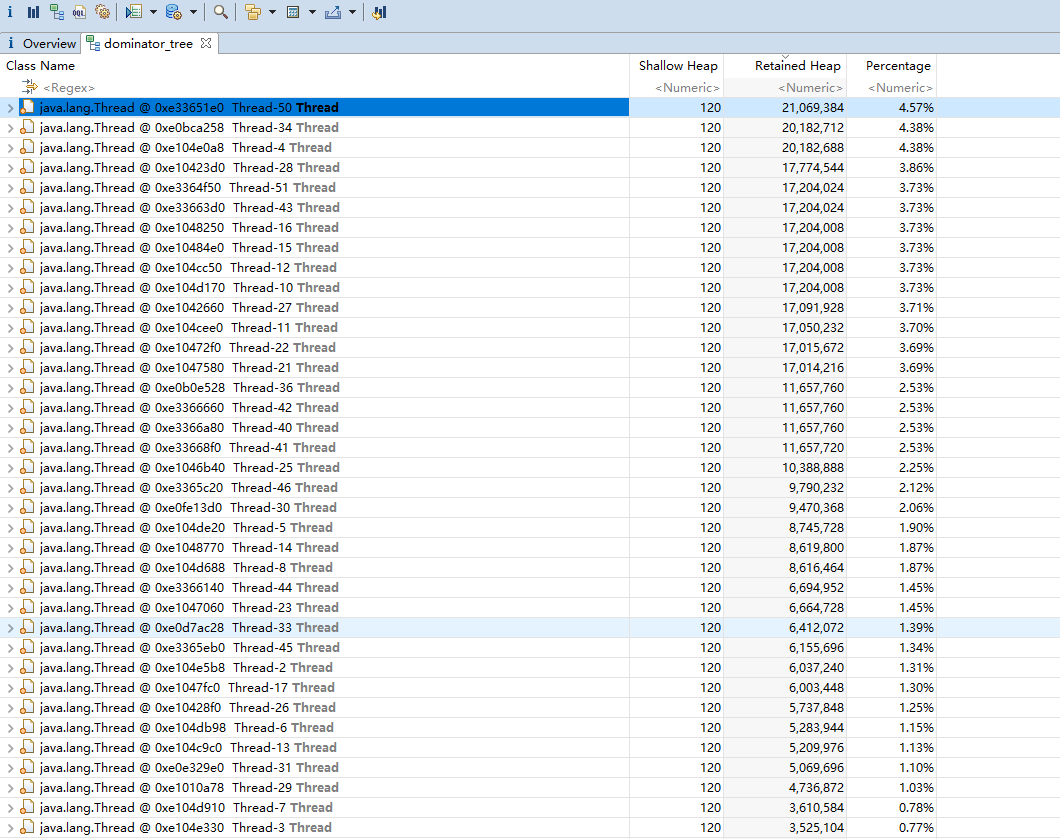
虽然没有出现一个对象占用内存,但是可以看到有十几个线程都占用近 20M 的内存大小,加起来就要占用 300 多 M 的内存了。再看一下这些线程中内存占用是怎样的。
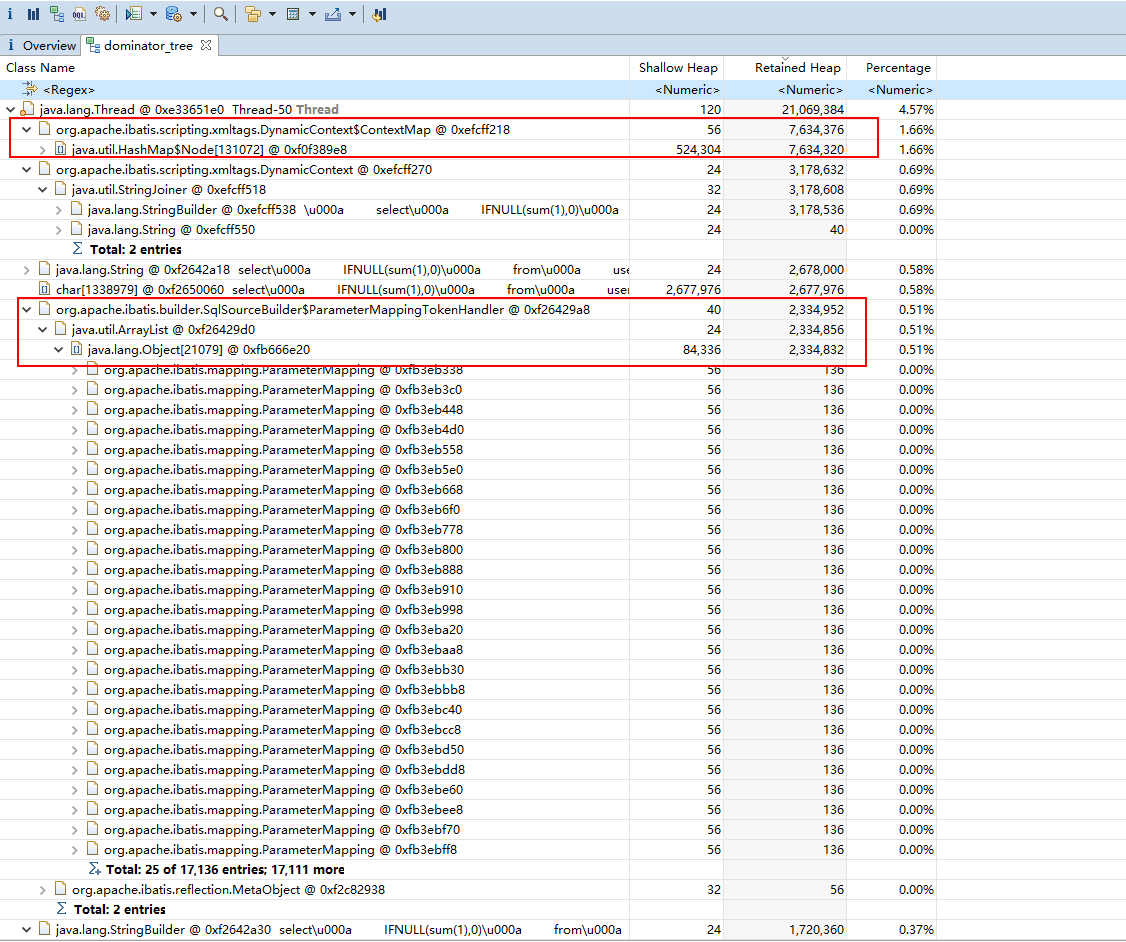
从这个线程的高占用内存情况来看,有几个是 String 类型的,是拼接 SQL 后的语句,这些是必不可少的。
还有两个高内存占用对象是org.apache.ibatis.scripting.xmltags.DynamicContext$ContextMap和org.apache.ibatis.builder.SqlSourceBuilder$ParameterMappingTokenHandler。
从这两个对象的内容看似乎是Mybatis拼接 SQL 的时候生成的占位符和参数对象。就比如下面的这个查询语句
List<Long> customerIds = orderService.queryCustomerIdByParam(param);
long principal = orderMapper.countPrincipal(customerIds);
所以虽然用于查询的参数为Long的类型,即使这个List有三万多个其本身也不会占用很大的内存,但是Mybatis在拼接 SQL 的时候,会把Long类型的对象包装成一个通用的对象类型(类似于 AbstractItem 的感觉),并且会给每一个通用对象类型起一个别名(比如__frch_item_1, __frch_item_2这样),然后存放在 Map 中在拼接 SQL 的时候使用。又由于拼接 SQL 字符串还是比较消耗资源,当参数多 SQL 长的时候还是需要一定的时间的,这时候 Map 就会持有较长时间,一旦有较多线程同时做这种操作,内存占用就高,很容易发生OOM。
查看Mybatis源码分析
首先看org.apache.ibatis.scripting.xmltags.DynamicContext$ContextMap,他是DynamicContext的一个变量,变量名为bindings,是DynamicContext的内部类,继承了HashMap。并且DynamicContext类里用了bind()方法包装了HashMap的put() 方法。
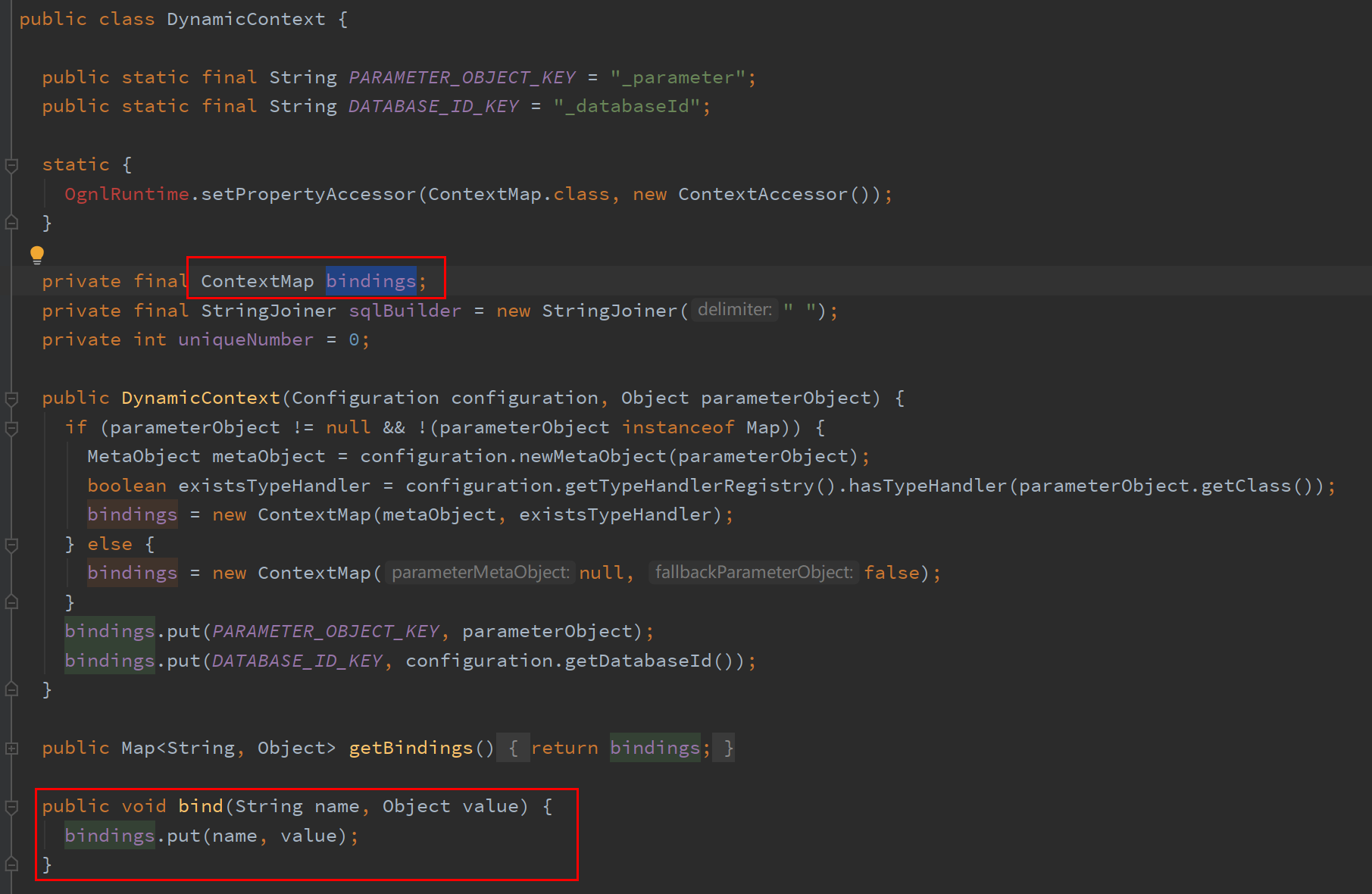
再利用 IDEA 的Usages of查看功能,看看哪些方法调用了bind()方法。
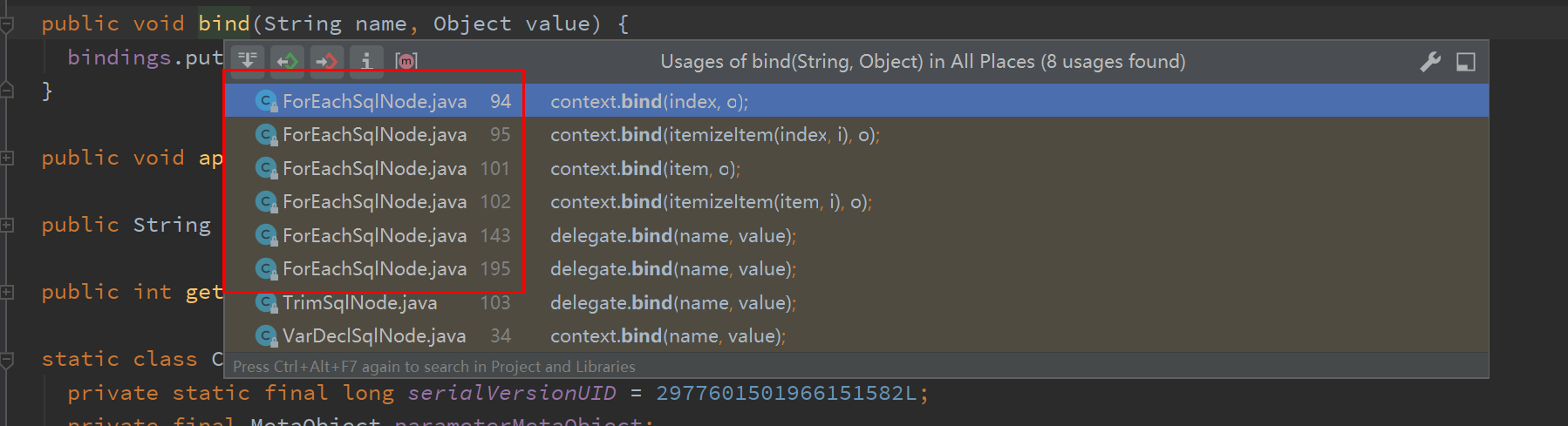
可以看到有三个类调用bind()方法,这里只用关注org.apache.ibatis.scripting.xmltags.ForEachSqlNode这个类,因为我们在Mybatis的xml里用了foreach关键字来实现 SQL 的 in 查询功能。那我们大致来看一下ForEachSqlNode这个类有什么特别的地方可能导致oom的。
ForEachSqlNode实现了SqlNode接口并实现了apply()方法,这个方法是拼接 SQL 语句的核心,下面是apply()方法的代码,我为一些关键步骤加了中文注释。
@Override
public boolean apply(DynamicContext context) {
// bindings 就是上面说到的占用大内存的对象
Map<String, Object> bindings = context.getBindings();
final Iterable<?> iterable = evaluator.evaluateIterable(collectionExpression, bindings);
if (!iterable.iterator().hasNext()) {
return true;
}
boolean first = true;
// SQL 的开始字符串
applyOpen(context);
int i = 0;
// 遍历参数
for (Object o : iterable) {
DynamicContext oldContext = context;
if (first || separator == null) {
context = new PrefixedContext(context, "");
} else {
context = new PrefixedContext(context, separator);
}
int uniqueNumber = context.getUniqueNumber();
// Issue #709
if (o instanceof Map.Entry) {
// 如果是 Map 对象则用 key value 的形式
@SuppressWarnings("unchecked")
Map.Entry<Object, Object> mapEntry = (Map.Entry<Object, Object>) o;
applyIndex(context, mapEntry.getKey(), uniqueNumber);
applyItem(context, mapEntry.getValue(), uniqueNumber);
} else {
// 以数量 i 作为 key
applyIndex(context, i, uniqueNumber);
applyItem(context, o, uniqueNumber);
}
// FilteredDynamicContext 动态生成 SQL
contents.apply(new FilteredDynamicContext(configuration, context, index, item, uniqueNumber));
if (first) {
first = !((PrefixedContext) context).isPrefixApplied();
}
context = oldContext;
i++;
}
// SQL 的结束字符串
applyClose(context);
context.getBindings().remove(item);
context.getBindings().remove(index);
return true;
}
在每个遍历的时候applyIndex()和applyItem()方法就会将参数和参数的占位符,以及参数 SQL 前后缀调用上面说的bind()方法存在bindings里。
private void applyIndex(DynamicContext context, Object o, int i) {
if (index != null) {
context.bind(index, o);
context.bind(itemizeItem(index, i), o);
}
}
private void applyItem(DynamicContext context, Object o, int i) {
if (item != null) {
context.bind(item, o);
context.bind(itemizeItem(item, i), o);
}
}
接着用FilteredDynamicContext处理占位符,这是ForEachSqlNode的一个内部类,继承了DynamicContext类,主要重写了appendSql()方法。
private static class FilteredDynamicContext extends DynamicContext {
...
@Override
public void appendSql(String sql) {
GenericTokenParser parser = new GenericTokenParser("#{", "}", content -> {
String newContent = content.replaceFirst("^\\s*" + item + "(?![^.,:\\s])", itemizeItem(item, index));
if (itemIndex != null && newContent.equals(content)) {
newContent = content.replaceFirst("^\\s*" + itemIndex + "(?![^.,:\\s])", itemizeItem(itemIndex, index));
}
return "#{" + newContent + "}";
});
delegate.appendSql(parser.parse(sql));
}
appendSql()用正则来查找替换#{}占位符里的内容,但这里也不是真正的绑定参数,只是替换刚才存在bindings里面的占位符号,例如__frch_item_1, __frch_item_2(在 Dump 文件中看到的)。
问题分析
由此可以看出问题是,Mybatis的foreach拼接 SQL 的性能较差,尤其是通过正则之类的操作匹配占位符时需要较多的时间。同时又持有查询参数和占位符在ContextMap中无法被 GC 释放,所以一旦并发量上去就很容易内存占用过多导致OOM。
场景复现
这个问题在本地很容易复现,我们先创建数据库表
CREATE TABLE user
(
id int(11) PRIMARY KEY NOT NULL,
name varchar(50)
);
创建一个SpringBoot+Mybatis的工程项目。并且模拟线上的 JVM 配置,在 IDEA 设置这个工程的VM Option参数-Xmx512m -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
写出对应模拟线上的foreach语句
<select id="countUser" resultType="long">
select
IFNULL(sum(1),0)
from user where
<if test="ids != null and ids.size() > 0">
id in
<foreach collection="ids" item="item" index="index" open="("
close=")" separator=",">
#{item}
</foreach>
</if>
</select>
再写单元测试
@Test
public void count() {
AtomicInteger count = new AtomicInteger(0);
for (int threadId = 0; threadId < 50; threadId++) {
// 起 50 个线程并发调用 countUser() 方法
int finalThreadId = threadId;
new Thread(() -> {
long userCount = userMapper.countUser(createIds(10000 + finalThreadId));
log.info("thread:{}, userCount:{}", finalThreadId, userCount);
count.getAndAdd(1);
}).start();
}
// 等待 50 个查询线程跑完
while (count.get() < 50) {
}
log.info("end!!!!");
}
private List<Long> createIds(int size) {
List<Long> ids = new ArrayList<>();
for (int i = 0; i < size; i++) {
ids.add((long) i);
}
return ids;
}
接着运行单元测试。由于在 JVM 配置加了-XX:+PrintGCDetails参数,所以在控制台会显示 GC 日志,不一会就会看见很多的 Full GC,然后程序就会出现OOM报错。

处理
由于问题是Mybatis通过foreach拼接长 SQL 字符串性能太差导致的,所以解决思路有两种
- 通过拆分 in 的查询条件来减少
foreach每次拼接 SQL 的长度
@Test
public void count2() {
AtomicInteger count = new AtomicInteger(0);
for (int threadId = 0; threadId < 50; threadId++) {
// 起 50 个线程并发调用 countUser() 方法
int finalThreadId = threadId;
new Thread(() -> {
List<Long> totalIds = createIds(100000 + finalThreadId);
long totalUserCount = 0;
//使用 guava 对 list 进行分割,按每 1000 个一组分割
List<List<Long>> parts = Lists.partition(totalIds, 1000);
for (List<Long> ids : parts) {
totalUserCount += userMapper.countUser(ids);
}
log.info("thread:{}, userCount:{}", finalThreadId, totalUserCount);
count.getAndAdd(1);
}).start();
}
// 等待 50 个查询线程跑完
while (count.get() < 50) {
}
log.info("end!!!!");
}
这样每次拼接查询 SQL 的时候只用循环 1000 次,很快就可以把资源释放掉,就不会引起OOM,但是这种方法还是会生成很多不必要的数据占用内存,频繁触发 GC,浪费资源。
- 不使用
Mybatis的foreach来拼接 in 条件的 SQL
既然Mybatis的foreach性能不好,那我们通过 Java 层面自己拼接 in 条件,特别是针对这种查询条件也比较单一的,更适合自己拼接。
@Test
public void count3() {
AtomicInteger count = new AtomicInteger(0);
for (int threadId = 0; threadId < 50; threadId++) {
// 起 50 个线程并发调用 countUser() 方法
int finalThreadId = threadId;
new Thread(() -> {
List<Long> ids = createIds(100000 + finalThreadId);
StringBuilder sb = new StringBuilder();
for (long i : ids) {
sb.append(i).append(",");
}
// 查询条件使用 String 字符串
long userCount = userMapper.countUserString(sb.toString());
log.info("thread:{}, userCount:{}", finalThreadId, userCount);
count.getAndAdd(1);
}).start();
}
// 等待 50 个查询线程跑完
while (count.get() < 50) {
}
log.info("end!!!!");
}
<select id="countUserString" resultType="long">
select
IFNULL(sum(1),0)
from user where
<if test="null != ids and ids !=''">
id in (#{ids})
</if>
</select>
这样就能大大减少使用foreach而生成的对象,同时减少拼接 SQL 的时间,避免OOM发生的同时优化性能。
后记
这两次遇到OOM问题解决起来还算比较轻松的,除了后续分析得当以外,也离不开预先的环境配置。在服务 JVM 参数中增加-XX:+HeapDumpOnOutOfMemoryError和-XX:+PrintGCDetails参数,可以在发生OOM的时候输出 dump 文件,并且能有 GC 日志查看 GC 的具体情况,这些都是对于OOM问题非常有帮助的。